
LLM là gì? Giải thích dễ hiểu về mô hình ngôn ngữ lớn cho người mới
- Minh Tuấn

- 1 ngày trước
- 12 phút đọc
LLM là gì là câu hỏi rất nhiều người đặt ra sau khi đã dùng ChatGPT, chatbot AI hoặc các công cụ Generative AI trong công việc hằng ngày. Bạn có thể đã dùng AI để viết nháp, tóm tắt tài liệu hoặc hỏi đáp nhanh, nhưng vẫn chưa thật sự hiểu mô hình đứng phía sau hoạt động ra sao. Bài viết này sẽ giải thích LLM bằng ngôn ngữ phổ thông, tập trung vào 4 ý cốt lõi: định nghĩa, cách hoạt động, ứng dụng thực tế và giới hạn cần lưu ý. Mục tiêu không phải biến bạn thành kỹ sư AI, mà giúp bạn có một khung hiểu đúng để dùng công nghệ này hiệu quả hơn.

LLM là gì? Định nghĩa dễ hiểu nhất cho người mới
LLM là viết tắt của Large Language Model, tức mô hình ngôn ngữ lớn được huấn luyện trên lượng dữ liệu văn bản rất lớn để hiểu và tạo ra ngôn ngữ tự nhiên. Đây là nền tảng đứng sau nhiều công cụ AI hiện nay như trợ lý viết, hệ thống hỏi đáp và chatbot thông minh.

Điểm quan trọng trong cụm từ “Large” không chỉ là dữ liệu lớn. Nó thường bao gồm 3 lớp ý nghĩa:
Dữ liệu huấn luyện lớn: mô hình học từ khối lượng văn bản rất lớn.
Quy mô mô hình lớn: có nhiều tham số để học các mẫu ngôn ngữ phức tạp.
Khả năng xử lý ngữ cảnh tốt hơn: thường hiểu mạch câu và đoạn tốt hơn mô hình nhỏ.
Nói đơn giản, mô hình ngôn ngữ lớn là một “động cơ ngôn ngữ” có thể đọc đầu vào, nhận diện ngữ cảnh và tạo phản hồi bằng văn bản tương đối tự nhiên. Một số ví dụ quen thuộc trên thị trường hiện nay gồm GPT của OpenAI, Claude của Anthropic, Gemini của Google và LLaMA của Meta.
LLM không phải là “biết mọi thứ”
Đây là điểm người mới rất dễ hiểu sai. LLM tạo phản hồi dựa trên xác suất ngôn ngữ, tức dự đoán chuỗi từ hoặc token phù hợp nhất theo ngữ cảnh, chứ không phải truy cập một “kho tri thức tuyệt đối” luôn đúng. Vì vậy, một câu trả lời có thể rất mượt, rất tự tin nhưng vẫn sai dữ kiện hoặc thiếu logic nghiệp vụ. Trả lời trôi chảy không đồng nghĩa với đúng sự thật.
Tại sao LLM lại trở thành nền tảng quan trọng của làn sóng AI hiện nay?
Giao tiếp bằng ngôn ngữ tự nhiên nên người dùng không cần biết kỹ thuật sâu vẫn có thể tương tác.
Hỗ trợ nhiều tác vụ trên cùng một nền tảng như viết, tóm tắt, hỏi đáp, phân loại nội dung.
Trở thành động cơ ngôn ngữ cho nhiều ứng dụng Generative AI trong công việc và học tập.
LLM hoạt động như thế nào theo cách dễ hiểu?
Nếu chỉ nhìn từ bên ngoài, LLM giống như đang trả lời ngay lập tức. Nhưng bên trong, mô hình vận hành theo một quy trình khá rõ: chia đầu vào thành token, đọc ngữ cảnh, dự đoán phần tiếp theo và lặp lại quá trình đó liên tục.
Chia văn bản thành token
Đọc ngữ cảnh đã có
Dự đoán token tiếp theo bằng xác suất
Lặp lại để tạo thành câu trả lời hoàn chỉnh
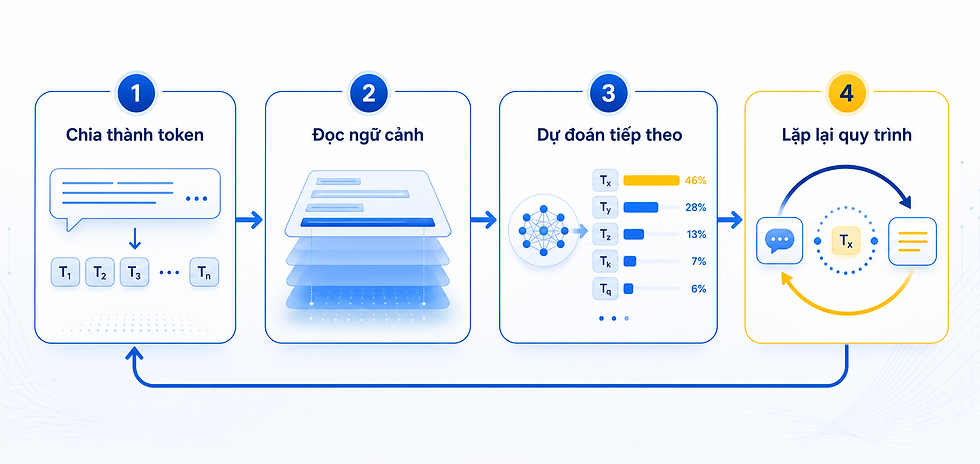
Bước 1: Văn bản được chia thành token
Token là đơn vị nhỏ mô hình dùng để xử lý văn bản. Token có thể là một từ, một phần của từ, hoặc thậm chí một ký tự tùy cách hệ thống tách dữ liệu. Quá trình này gọi là tokenization.
Ví dụ, câu “Tôi đang học AI” không nhất thiết được mô hình đọc như một khối hoàn chỉnh. Thay vào đó, nó có thể bị tách thành nhiều đơn vị nhỏ để xử lý tuần tự. Điều này giúp mô hình làm việc với ngôn ngữ theo dạng số hóa, thay vì “đọc” như con người.
Bước 2: Mô hình xem ngữ cảnh và đoán phần tiếp theo
Bản chất cốt lõi của LLM là next-word prediction hay dự đoán token tiếp theo. Mô hình nhìn vào chuỗi ngữ cảnh đang có, sau đó ước lượng token nào phù hợp nhất để đi tiếp.
Bạn có thể hình dung nó giống một dạng “điền vào chỗ trống thông minh”, nhưng ở mức phức tạp hơn rất nhiều. Nó không chỉ đoán một từ ngẫu nhiên, mà cân nhắc toàn bộ ngữ cảnh trước đó để chọn ra đầu ra có xác suất hợp lý nhất. Quá trình này lặp lại từng token một cho đến khi tạo thành câu trả lời hoàn chỉnh.
Bước 3: Transformer và self-attention giúp hiểu mối liên hệ trong câu
Hầu hết các LLM hiện nay sử dụng kiến trúc Transformer. Trong đó, cơ chế self-attention giúp mô hình nhận diện được các từ quan trọng trong câu, từ đó nắm bắt mối quan hệ ngữ nghĩa chính xác hơn.
Ví dụ, trong một câu dài có từ “nó”, mô hình cần nhìn lại chủ thể trước đó để hiểu “nó” đang chỉ ai hoặc chỉ điều gì. Self-attention hỗ trợ việc này bằng cách cho mô hình “chú ý” đến những phần liên quan trong toàn bộ câu hoặc đoạn, thay vì chỉ nhìn từng từ riêng lẻ. Đây là lý do LLM có thể giữ được mạch văn tốt hơn nhiều hệ thống cũ.
Bước 4: Huấn luyện trên dữ liệu lớn để phản hồi linh hoạt hơn
LLM được huấn luyện trên training data là lượng văn bản rất lớn từ nhiều nguồn khác nhau. Giai đoạn đầu, mô hình sẽ học các cấu trúc ngôn ngữ tổng quát. Sau đó, nó được tinh chỉnh để thực hiện các mục tiêu cụ thể, hay còn gọi là kỹ thuật fine-tuning.
Hiểu đơn giản:
Pretraining: học ngôn ngữ ở quy mô lớn.
Fine-tuning: tinh chỉnh cho một nhiệm vụ hoặc lĩnh vực cụ thể.
Ngoài ra, mỗi mô hình đều có context window – giới hạn lượng thông tin nó có thể xử lý trong một lượt. Nếu đầu vào quá dài hoặc quá nhiều chi tiết, mô hình có thể bỏ sót một phần ngữ cảnh. Đây là cách giải thích đơn giản hóa, giúp người mới nắm bắt được cơ chế vận hành cốt lõi.
LLM khác gì với ChatGPT, chatbot, Generative AI và AI Agent?
Một trong những nhầm lẫn phổ biến nhất của người mới là xem ChatGPT, chatbot, Generative AI và LLM như cùng một thứ. Thực tế, chúng nằm ở các tầng khái niệm khác nhau.
Điểm cần nhớ là: LLM là model, tức lõi công nghệ. ChatGPT là một ứng dụng sử dụng LLM. Chatbot có thể dùng hoặc không dùng LLM. Generative AI là nhóm công nghệ rộng hơn. Còn AI Agent là tầng hệ thống cao hơn, nơi LLM chỉ là một thành phần trong toàn bộ quy trình.
Bảng phân biệt khái niệm dễ nhầm
Khái niệm | Bản chất | Ví dụ | Điểm khác chính |
LLM | Mô hình ngôn ngữ lớn | GPT, Claude, Gemini, LLaMA | Là lõi công nghệ |
ChatGPT | Ứng dụng dùng LLM | ChatGPT | Là sản phẩm, không phải toàn bộ công nghệ |
Chatbot truyền thống | Bot theo quy tắc hoặc kịch bản | Bot CSKH rule-based | Ít linh hoạt hơn |
Generative AI | Nhóm AI tạo sinh nội dung | Tạo text, ảnh, âm thanh | Phạm vi rộng hơn LLM |
AI Agent | Hệ thống AI có thể dùng công cụ và thực thi tác vụ | Agent lập báo cáo, tra cứu, gửi task | LLM chỉ là một phần trong hệ thống |
Nếu cần tóm gọn hơn:
LLM là foundation model cho ngôn ngữ.
ChatGPT là sản phẩm dùng một hoặc nhiều LLM.
Chatbot là hình thức giao diện hội thoại, có thể rất đơn giản hoặc rất thông minh.
Generative AI bao quát cả text, hình ảnh, âm thanh, video.
AI Agent là hệ thống có thể lập kế hoạch, gọi công cụ và thực hiện chuỗi tác vụ.
Điều này cũng có nghĩa: ChatGPT không đại diện cho toàn bộ AI, và LLM cũng không đồng nghĩa với mọi ứng dụng AI trên thị trường.
LLM có thể làm được gì trong thực tế?
Hiểu LLM sẽ dễ hơn nhiều nếu nhìn vào các việc nó làm tốt trong thực tế. Điểm mạnh cốt lõi của mô hình này là xử lý ngôn ngữ: đọc, viết, tóm tắt, diễn giải và hỗ trợ trao đổi thông tin.
Ứng dụng gần với người đi làm văn phòng
Viết nháp email, biên bản họp, proposal hoặc tài liệu nội bộ.
Tóm tắt tài liệu dài để tiết kiệm thời gian đọc.
Gợi ý cấu trúc trình bày ý tưởng hoặc nội dung đào tạo cơ bản.
Hoạt động như chatbot AI để trả lời câu hỏi thường gặp.
Hỗ trợ viết nội dung ban đầu trước khi con người chỉnh sửa lại.
Ứng dụng gần với analyst và manager
Hỏi dữ liệu bằng ngôn ngữ tự nhiên thay vì chỉ dựa vào cú pháp kỹ thuật.
Giải thích KPI, chỉ số và insight theo ngôn ngữ dễ hiểu hơn.
Hỗ trợ viết SQL hoặc DAX nháp ở mức sơ bộ.
Tăng tốc các tác vụ phân tích dữ liệu ban đầu.
Hỗ trợ diễn giải dashboard trong bối cảnh Business Intelligence.
Tóm tắt insight để chuẩn bị báo cáo cho quản lý hoặc C-level.

Trong thực tế, ứng dụng của LLM mạnh nhất ở các tác vụ liên quan đến ngôn ngữ và diễn giải thông tin. Tuy nhiên, với dữ liệu và BI, LLM nên được xem là công cụ hỗ trợ tăng tốc tư duy sơ bộ, không phải công cụ thay thế hoàn toàn chuyên môn phân tích hay quy trình kiểm tra số liệu.
Đội ngũ của bạn đang tìm hướng ứng dụng AI an toàn hơn trong phân tích và báo cáo? Xem thêm định hướng thực chiến tại https://www.mastering-da.com/agentic-ai-analytics-program.
Hạn chế và rủi ro của LLM: Vì sao không nên tin tuyệt đối vào AI?
Nhiều người mới hiểu sai về LLM vì những câu trả lời của AI thường rất trôi chảy và tự tin, dù có thể sai lệch về dữ kiện, nguồn dẫn hoặc logic. Hạn chế của LLM là có thật, và không phải ngoại lệ hiếm gặp.
Các rủi ro phổ biến gồm:
Hallucination hoặc ảo giác AI
Thiên lệch dữ liệu do mô hình học từ dữ liệu không hoàn hảo
Thiếu ngữ cảnh nội bộ của doanh nghiệp
Rủi ro bảo mật dữ liệu khi nhập thông tin nhạy cảm
Giới hạn trong việc hiểu bối cảnh chuyên sâu theo ngành
Hiểu đúng về “ảo giác” của AI
Hallucination là hiện tượng LLM tạo ra câu trả lời nghe hợp lý và trôi chảy nhưng thực tế sai, thiếu chính xác hoặc bịa nguồn. Nguyên nhân không phải vì AI cố ý nói dối, mà vì mô hình tối ưu xác suất ngôn ngữ chứ không luôn xác minh sự thật.
Vì vậy, nếu bạn thấy AI trả lời rất tự nhiên, điều đó mới chỉ cho thấy nó giỏi tạo ngôn ngữ. Nó không tự động chứng minh rằng nội dung đó chính xác. Đây là lý do nhiều người dùng mới đánh giá quá cao mô hình sau vài trải nghiệm ban đầu.
Khi nào cần kiểm chứng đầu ra của LLM?
Khi dùng cho báo cáo, tài chính, pháp lý hoặc tài liệu chính thức.
Khi phản hồi có số liệu, nguồn dẫn hoặc trích dẫn cụ thể.
Khi nội dung liên quan dữ liệu nội bộ hoặc quyết định quản trị.
Khi câu trả lời có thể ảnh hưởng đến khách hàng, nhân sự hoặc vận hành.
Không nên nhập dữ liệu nhạy cảm vào công cụ AI công cộng nếu chưa hiểu rõ chính sách lưu trữ và quyền riêng tư của nền tảng. Trong môi trường làm việc thật, nguyên tắc an toàn nên là Human-in-the-Loop – tức con người vẫn kiểm tra, phê duyệt và chịu trách nhiệm cuối cùng cho đầu ra.

⚠️ Lưu ý: Một mô hình trả lời tốt trong hội thoại không có nghĩa là phù hợp để đưa ra quyết định công việc mà không qua kiểm chứng.
Nếu bạn đang đánh giá cách đưa AI vào quy trình phân tích hoặc đào tạo nội bộ, nên bắt đầu từ use case nhỏ, có tiêu chí kiểm tra rõ ràng và cơ chế phê duyệt đầu ra.
Sau khi hiểu LLM, nên học gì tiếp theo?
Khi đã hiểu LLM là gì và hoạt động ra sao, bước tiếp theo không phải là lao ngay vào thuật ngữ phức tạp, mà là học những chủ đề giúp bạn dùng AI đúng và hữu ích hơn.
Lộ trình học tiếp gợi ý cho người mới
Prompt Engineering cơ bảnHọc cách đặt câu hỏi rõ ràng, có ngữ cảnh và có tiêu chí đầu ra.
Cách kiểm tra độ tin cậy của đầu raBiết khi nào cần đối chiếu nguồn, kiểm tra số liệu và xác minh logic.
Tìm hiểu RAG (Retrieval-Augmented Generation - tạo sinh tăng cường truy xuất)Đây là cách giúp LLM dựa trên nguồn tài liệu đáng tin cậy hơn thay vì chỉ trả lời từ xác suất ngôn ngữ.
Mở rộng sang AI Agent và orchestration ở mức ứng dụngHiểu cách AI không chỉ trả lời, mà còn phối hợp công cụ và quy trình để hỗ trợ công việc.

Với người làm dữ liệu hoặc BI, nên học thêm Semantic Model - lớp ngữ nghĩa giúp AI hiểu đúng định nghĩa chỉ số, bảng dữ liệu và bối cảnh nghiệp vụ. Đây là nền tảng quan trọng nếu bạn muốn đi xa hơn từ chatbot hỏi đáp sang hệ thống Agentic AI Analytics thực tế.
Gặp khó khăn trong việc xác định lộ trình học AI cho đội ngũ dữ liệu và quản lý? Tìm hiểu thêm chương trình định hướng ứng dụng tại https://www.mastering-da.com/agentic-ai-analytics-program.
Kết luận
Tóm lại, LLM là mô hình ngôn ngữ lớn đóng vai trò nền tảng cho nhiều công cụ AI. Chúng hoạt động dựa trên việc dự đoán các từ tiếp theo bằng xác suất và ngữ cảnh được thiết lập sẵn. Điểm mạnh của nó nằm ở khả năng xử lý ngôn ngữ tự nhiên, nhưng đi cùng với đó là các giới hạn rõ ràng như hallucination, thiếu bối cảnh nội bộ và rủi ro bảo mật nếu dùng sai cách.
Cách tiếp cận thực tế nhất là hiểu đúng trước, dùng có kiểm chứng sau. Nếu bạn muốn đi sâu hơn sau bài nhập môn này, nên đọc tiếp các chủ đề như Prompt Engineering, RAG, Semantic Model và cách AI Agent được ứng dụng trong môi trường Business Intelligence hiện đại.
Câu Hỏi Thường Gặp
LLM là gì?
LLM (Large Language Model) là mô hình trí tuệ nhân tạo được huấn luyện trên khối lượng văn bản khổng lồ để hiểu, dự đoán và tạo ra ngôn ngữ tự nhiên. Đây là nền tảng cốt lõi đứng sau các ứng dụng AI hiện đại như ChatGPT, Claude hay Gemini.
LLM hoạt động như thế nào?
LLM hoạt động dựa trên việc chia nhỏ văn bản thành các đơn vị gọi là "token", sau đó sử dụng kiến trúc Transformer để phân tích mối quan hệ ngữ cảnh và dự đoán xác suất của token tiếp theo trong chuỗi, từ đó hình thành câu trả lời hoàn chỉnh.
LLM khác gì với ChatGPT, chatbot và AI Agent?
LLM là "bộ não" công nghệ (mô hình). ChatGPT là một ứng dụng sản phẩm sử dụng LLM. Chatbot truyền thống hoạt động theo kịch bản cứng nhắc, còn AI Agent là hệ thống tự chủ có thể dùng công cụ, quy trình và dữ liệu để thực hiện tác vụ phức tạp.
LLM có thể làm được gì trong công việc thực tế?
LLM hỗ trợ đắc lực các tác vụ ngôn ngữ như: viết nháp email, tóm tắt tài liệu, biên dịch, diễn giải chỉ số dữ liệu, hỗ trợ viết code sơ bộ và đóng vai trò như trợ lý thông minh giúp tăng tốc quy trình xử lý thông tin hàng ngày.
Tại sao LLM lại dễ tạo ra thông tin sai lệch (ảo giác)?
LLM hoạt động dựa trên xác suất dự đoán từ ngữ thay vì "hiểu" sự thật khách quan. Do đó, nếu dữ liệu huấn luyện không đầy đủ hoặc mô hình gặp câu hỏi phức tạp, nó có thể tạo ra các câu trả lời nghe rất thuyết phục nhưng sai sự thật (hiện tượng ảo giác).
Người mới nên bắt đầu học gì sau khi hiểu về LLM?
Bạn nên bắt đầu với kỹ năng đặt câu lệnh (Prompt Engineering), học cách kiểm chứng đầu ra của AI, tìm hiểu về RAG (kết hợp dữ liệu nội bộ với LLM) và cách vận hành các hệ thống AI có sự giám sát của con người (Human-in-the-Loop) để đảm bảo tính an toàn.



Bình luận